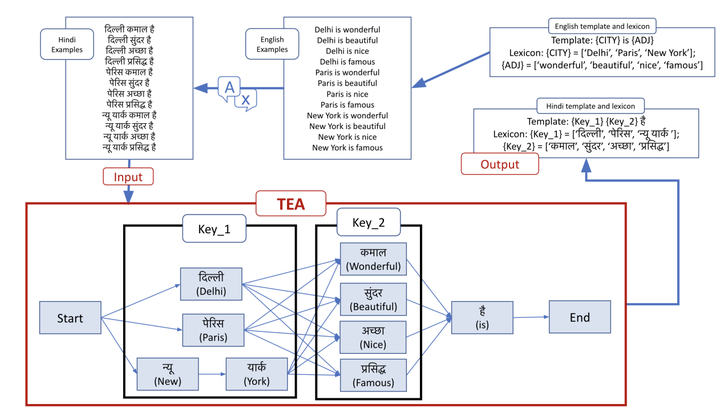
The recently proposed CheckList (Riberio et al,. 2020) approach to evaluation of NLP systems has revealed high failure rates for basic capabilities for multiple state-of-the-art and commercial models. However, the CheckList creation process is manual which creates a bottleneck towards creation of multilingual CheckLists catering 100s of languages. In this work, we explore multiple approaches to generate and evaluate the quality of Multilingual CheckList. We device an algorithm – Automated Multilingual Checklist Generation (AMCG) for automatically transferring a CheckList from a source to a target language that relies on a reasonable machine translation system. We then compare the CheckList generated by AMCG with CheckLists generated with different levels of human intervention. Through in-depth crosslingual experiments between English and Hindi, and broad multilingual experiments spanning 11 languages, we show that the automatic approach can provide accurate estimates of failure rates of a model across capabilities, as would a human-verified CheckList, and better than CheckLists generated by humans from scratch.