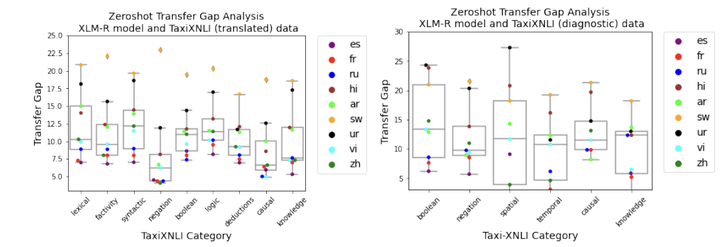
Multilingual language models achieve impressive zero-shot accuracies in many languages in complex tasks such as Natural Language Inference (NLI). Examples in NLI (and equivalent complex tasks) often pertain to various types of sub-tasks, requiring different kinds of reasoning. Certain types of reasoning have proven to be more difficult to learn in a monolingual context, and in the crosslingual context, similar observations may shed light on zero-shot transfer efficiency and few-shot sample selection. Hence, to investigate the effects of types of reasoning on transfer performance, we propose a category-annotated multilingual NLI dataset. We discuss the challenges to scale monolingual annotations to multiple languages. We statistically observe interesting effects that the confluence of reasoning types and language similarities have on transfer performance.