LITMUS Predictor: An AI Assistant for Building Reliable, High-Performing and Fair Multilingual NLP Systems
Type
Publication
In AAAI 2022 Demonstrations
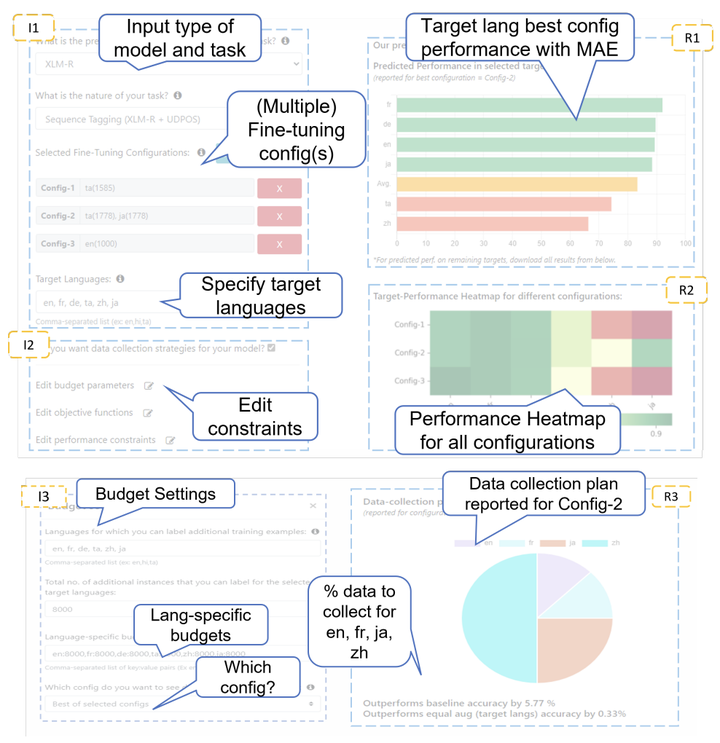
Pre-trained multilingual language models are gaining popularity due to their cross-lingual zero-shot transfer ability, but these models do not perform equally well in all languages. Evaluating task-specific performance of a model in a large number of languages is often a challenge due to lack of labeled data, as is targeting improvements in low performing languages through few-shot learning. We present a tool - LITMUS Predictor - that can make reliable performance projections for a fine-tuned task-specific model in a set of languages without test and training data, and help strategize data labeling efforts to optimize performance and fairness objectives.