STUCK IN THE QUICKSAND OF NUMERACY, FAR FROM AGI SUMMIT: EVALUATING LLMS' MATHEMATICAL COMPETENCY THROUGH ONTOLOGY-GUIDED PERTURBATIONS
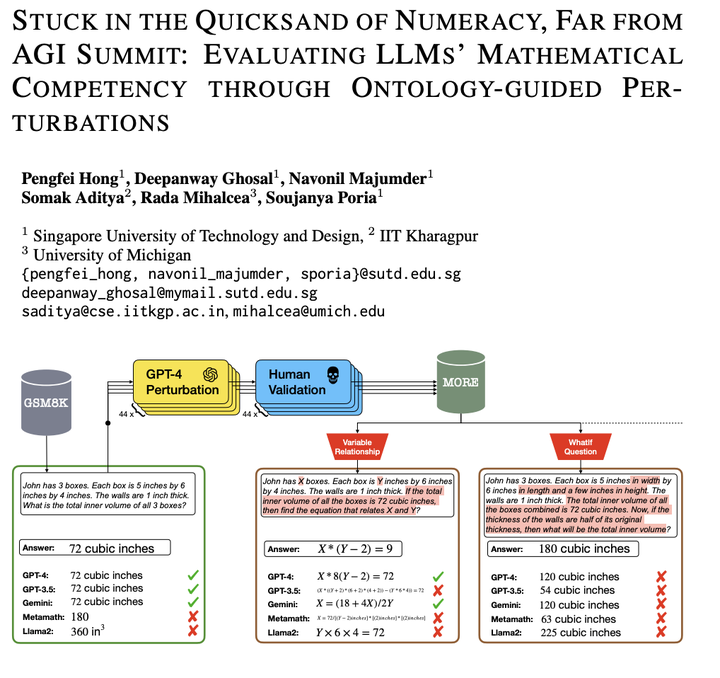
Recent advancements in Large Language Models (LLMs) have showcased striking results on existing logical reasoning benchmarks, with some models even surpassing human performance. However, the true depth of their competencies and robustness, in mathematical reasoning tasks, remains an open question. In response, we develop (i) an ontology of perturbations of maths questions, (ii) a semi-automatic method of perturbation, and (iii) a dataset of perturbed maths questions to probe the limits of LLM capabilities in mathematical-reasoning tasks. These controlled perturbations span across multiple fine dimensions of the structural and representational aspects of maths questions. Using GPT-4, we generated the More dataset by perturbing randomly selected five seed questions from GSM8K. This process was guided by our ontology and involved a thorough automatic and manual filtering process, yielding a set of 216 maths problems. We conducted comprehensive evaluation of both closed-source and open-source LLMs on More. The results show a significant performance drop across all the models against the perturbed questions. This strongly suggests that current LLMs lack robust mathematical skills and a deep understanding of reasoning. This research not only identifies multiple gaps in the capabilities of current models, but also highlights multiple potential directions for future development. Our dataset will be made publicly available at huggingface library.