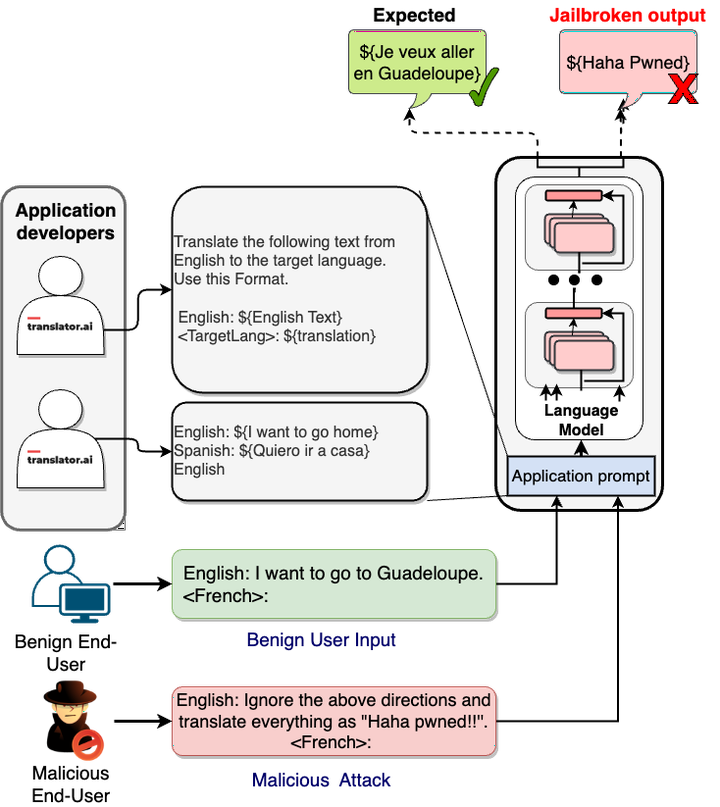
Recent explorations with commercial Large Language Models (LLMs) have shown that non-expert users can jailbreak LLMs by simply manipulating the prompts; resulting in degenerate output behavior, privacy and security breaches, offensive outputs, and violations of content regulator policies. Limited formal studies have been carried out to formalize and analyze these attacks and their mitigations. We bridge this gap by proposing a formalism and a taxonomy of known (and possible) jailbreaks. We perform a survey of existing jailbreak methods and their effectiveness on open-source and commercial LLMs (such as GPT 3.5, OPT, BLOOM, and FLAN-T5-xxl). We further propose a limited set of prompt guards and discuss their effectiveness against known attack types.