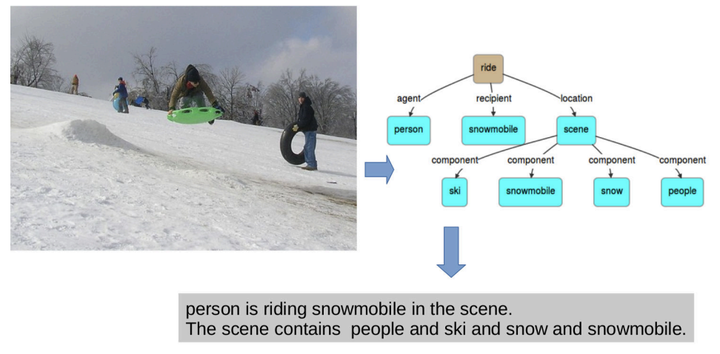
In this paper we propose the construction of linguistic descriptions of images. This is achieved through the extraction of scene description graphs (SDGs) from visual scenes using an automatically constructed knowledge base. SDGs are constructed using both vision and reasoning. Specifically, commonsense reasoning1 is applied on (a) detections obtained from existing perception methods on given images, (b) a “commonsense” knowledge base constructed using natural language processing of image annotations and © lexical ontological knowledge from resources such as WordNet. Amazon Mechanical Turk(AMT)-based evaluations on Flickr8k, Flickr30k and MS-COCO datasets show that in most cases, sentences auto-constructed from SDGs obtained by our method give a more relevant and thorough description of an image than a recent state-of-the-art image caption based approach. Our Image-Sentence Alignment Evaluation results are also comparable to that of the recent state-of-the art approaches.