Text2Afford: Probing Object Affordance Prediction abilities of Language Models solely from Text
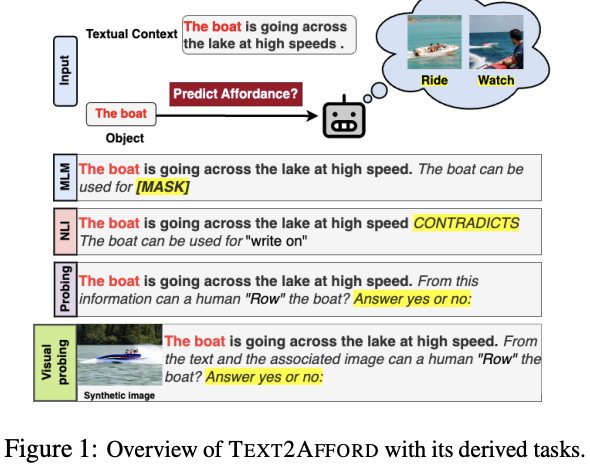
We investigate the knowledge of object affordances in pre-trained language models (LMs) and pre-trained Vision-Language models (VLMs). A growing body of literature shows that PTLMs fail inconsistently and nonintuitively, demonstrating a lack of reasoning and grounding. To take a first step toward quantifying the effect of grounding (or lack thereof), we curate a novel and comprehensive dataset of object affordances – TEXT2AFFORD, characterized by 15 affordance classes. Unlike affordance datasets collected in vision and language domains, we annotate in-the-wild sentences with objects and affordances. Experimental results reveal that PTLMs exhibit limited reasoning abilities when it comes to uncommon object affordances. We also observe that pretrained VLMs do not necessarily capture object affordances effectively. Through few-shot fine-tuning, we demonstrate improvement in affordance knowledge in PTLMs and VLMs. Our research contributes a novel dataset for language grounding tasks, and presents insights into LM capabilities, advancing the understanding of object affordances.