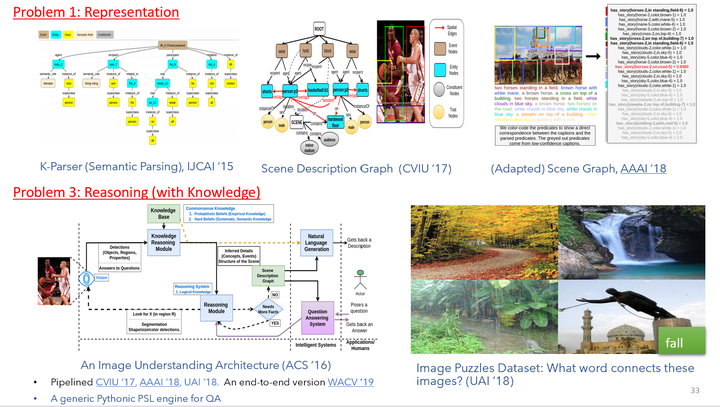
Image Understanding is a long-established discipline in computer vision, which encompasses a body of advanced image processing techniques, that are used to locate (“where”), characterize and recognize (“what”) objects, regions, and their attributes in the image. However, the notion of “understanding” (and the goal of artificial intelligent machines) goes beyond factual recall of the recognized components and includes reasoning and thinking beyond what can be seen (or perceived). Understanding is often evaluated by asking questions of increasing difficulty. Thus, the expected functionalities of an intelligent Image Understanding system can be expressed in terms of the functionalities that are required to answer questions about an image. Answering questions about images require primarily three components: Image Understanding, question (natural language) understanding, and reasoning based on knowledge. Any question, asking beyond what can be directly seen, requires modeling of commonsense (or background/ontological/factual) knowledge and reasoning.
Knowledge and reasoning have seen scarce use in image understanding applications. In this thesis, we demonstrate the utilities of incorporating background knowledge and using explicit reasoning in image understanding applications. We first present a comprehensive survey of the previous work that utilized background knowledge and reasoning in understanding images. This survey outlines the limited use of commonsense knowledge in high-level applications. We then present a set of vision and reasoning-based methods to solve several applications and show that these approaches benefit in terms of accuracy and interpretability from the explicit use of knowledge and reasoning. We propose novel knowledge representations of image, knowledge acquisition methods, and a new implementation of an efficient probabilistic logical reasoning engine that can utilize publicly available commonsense knowledge to solve applications such as visual question answering, image puzzles. Additionally, we identify the need for new datasets that explicitly require external commonsense knowledge to solve. We propose the new task of Image Riddles, which requires a combination of vision, and reasoning based on ontological knowledge; and we collect a sufficiently large dataset to serve as an ideal testbed for vision and reasoning research. Lastly, we propose end-to-end deep architectures that can combine vision, knowledge and reasoning modules together and achieve large performance boosts over state-of-the-art methods