Reasoning in NLP
Models that claim to understand language, should also be able to demonstrate its abilities to reason across various dimensions. My present goal is to evaluate, enhance and explain the reasoning capabilities of such systems (or language models).
!!NEW!! Reasoning in LLMs
Our group has invested significantly in advancing reasoning abilities of LLMs in a multi-hop setting. The following drafts are in progress: 1) RelSelect$^+$: Efficient Leaf Selection to Improve Entailment Tree Generation, 2) LogicPO: Efficient Translation of NL-based Logical Problems to FOL using LLMs and Preference Optimization (under review COLM 2025), and 3) Multi-step Logical Reasoning under Incomplete Knowledge.References
- Code Prompting Elicits Conditional Reasoning Abilities in Text+Code LLMs, Haritz Puerto1, Martin Tutek1, Somak Aditya2, Xiaodan Zhu1,3, Iryna Gurevych1 1Ubiquitous Knowledge Processing Lab (UKP Lab),TU Darmstadt and Hessian Center for AI (hessian.AI) 2IIT Kharagpur, 2Queen’s University, EMNLP 2024 (Main) !!NEW!!
- Towards LogiGLUE: A Brief Survey and A Benchmark for Analyzing Logical Reasoning Capabilities of Language Models, Man Luo1,2, Shrinidhi Kumbhar1, Ming shen,1 Mihir Parmar1, Neeraj Varshney1, Pratyay Banerjee3, Somak Aditya4, Chitta Baral1, 1Arizona State University, 2Mayo Clinic, 3Amazon Alexa AI, 4IIT KGP ArXiv Nov 2023 !!NEW!!
- Generating Intermediate Steps for NLI with Next-Step Supervision, AACL-IJCNLP 2023, Main !!NEW!!
Natural Language Inference
Large pre-trained language models show high performance in popular NLP benchmarks (GLUE, SuperGLUE), while failing poorly in datasets with targeted linguistic and logical phenomena. We consolidate the interesting reasoning phenomena in Taxonomy of reasoning w.r.t the NLI task. Our first work along this line published in CoNLL 2020 showed that these models (BERT, RoBERTa) may not know how to perform certain types of reasoning such as causal, numeric, spatial, temporal; but they can identify the type of reasoning required for a new example.We did a follow-up, adapting the CheckList methodology, where we create a large CheckList-NLI dataset to individually yet collectively test different reasoning capabilities, including pragmatic ones. Through our test-suite, we show that such a post-hoc evaluation provides a more comprehensive overview of the behavioral nature of the language models. A thorough human study with Linguistic Olympiad participants shows that behavioral summary leads to better explanation and RoBERTa’s behavior is more predictable than BERT. Currently, we are also exploring augmenting NLI datasets with verifiable proofs.
Summary and Extensions:
- TaxiNLI: Taxonomic Fragmentation of the NLI Task, CoNLL 2020
- TaxiXNLI: Multi-lingual Extension of TaxiNLI, EMNLP 2021 MRL Workshop
- LoNLI: Testing Diverse Reasoning of NLI Systems, LREV 2023, In Print, !!NEW!!
Enhancing NLI: Multi-hop, Causality and Counterfactuals & Reasoning in LLMs
As observed through TaxiNLI family of work, language models struggle with many important reasoning types. With Deepanway Ghoshal and Monojit choudhury, we explored a less annotation-intensive way to generate intermediate steps for complex reasoning examples in free-form NLI datasets. We observe, not only, we can generate such multi-hop steps without end-to-end supervision; but the steps are accurate as they can be augmented directly to improve NLI model's predictive ability.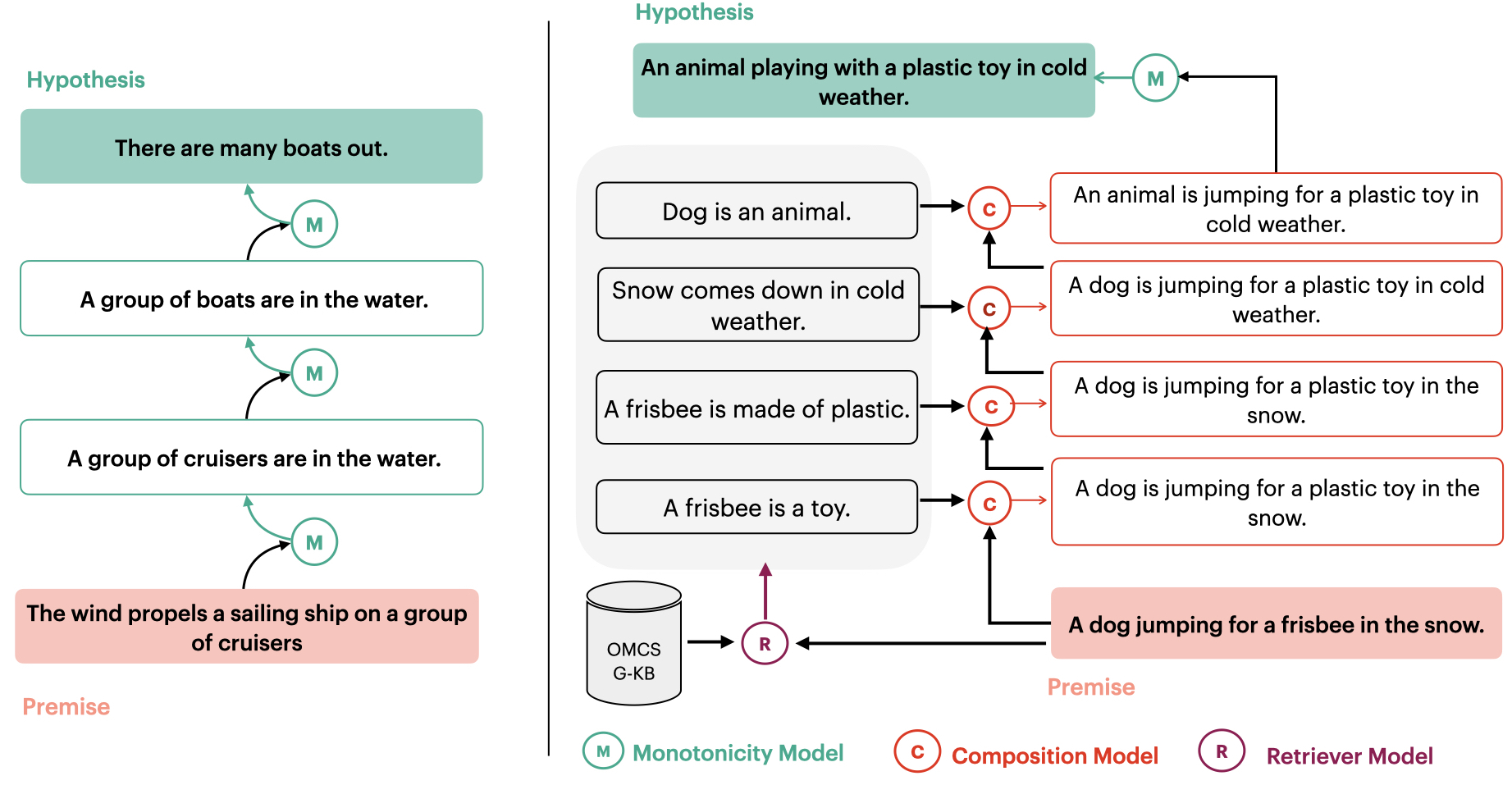
References
- Generating Intermediate Steps for NLI with Next-Step Supervision, AACL-IJCNLP 2023, Main !!NEW!!
Previously I have been interested in mapping natural language to formal language representation and reasoning with it. My proposed solutions towards Question-Answering and Winograd Schema Challenge during my Ph.D have been motivated by the central idea of semantic parsing, followed by logical (or probabilistic logical) reasoning.
Semantic Parsing (K-Parser)
We (led by co-authors Arpit Sharma and Nguyen Vo) have explored mapping of natural language to formal representation, that enbales logical reasoning. Through several papers (K-Parser IJCAI-15, K-Parser NAACL 15), we showed how such semantic parsing enables us to find event mentions, and (even patially but interpretably) solved Winograd Schema challenge problems.Somak Aditya
Assistant Professor
My research interests include integrating knowledge and enabling higher-order reasoning in AI.
Publications
(2025).
(2025).
(2024).
(2023).
(2023).
(2019).