LOGICPO: Efficient Translation of NL-based Logical Problems to FOL using LLMs and Preference Optimization
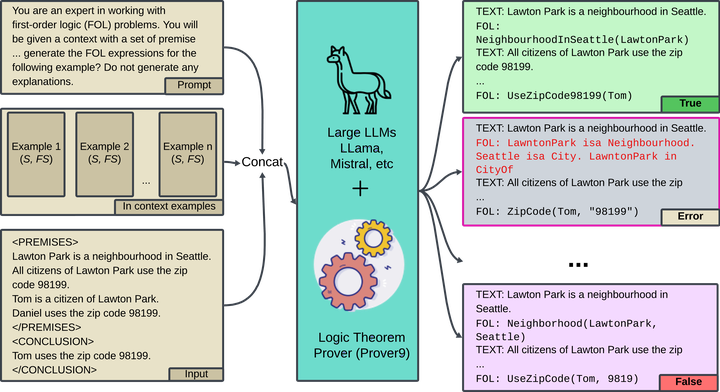
Logical reasoning is a key task for artificial intelligence due to it’s role in major downstream tasks such as Question Answering, Summarization. Recent neurosymbolic methods in improving the reasoning ability of Large Language Models (LLM) fall short in correctly converting a natural language reasoning problem to an equivalent logical formulation, which hinders the framework’s overall ability to reason. Towards this, we propose to use finetuning on a preference optimization dataset to learn to translate a natural language reasoning problem in its entirety to a consistent logical program by 1) introducing a new supervised and preference optimization dataset (LOGICPO), and 2) adopting popular techniques such as Direct Preference Optimization (DPO), Kahneman-Tversky optimization (KTO) to finetune open-source LLMs. Our best model with QWEN-2.5 (14B) consistently outperforms GPT-4’s (8-shot) by producing 6% more logically correct and with 8% less syntax errors. We show that translating problems as a whole significantly surpasses sentence-wise text to First order Logic (FOL) baselines. We further explicitly discuss the categories of errors that our framework addresses (and does not address), in the context of recent comparable Neurosymbolic provers.