SYNC: A Structurally guided Hard Negative Curricula for Efficient Neural Code Search
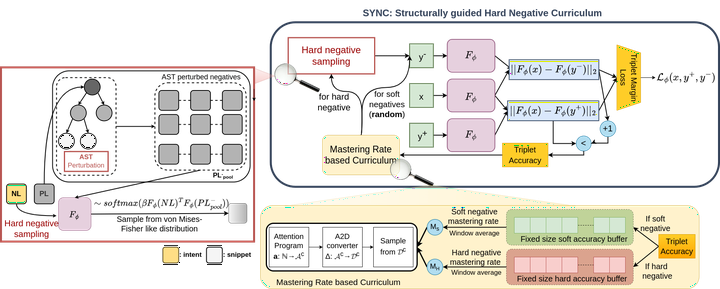
In neural code search, a Transformers-based pre-trained language model (such as CodeBERT) is used to embed both the query (NL) and the code snippet (PL) into a joint representation space; which is used to retrieve the relevant PLs satisfying the query. These models often make mistakes such as retrieving snippets with incorrect data types, and incorrect method names or signatures. The generalization ability beyond training data is also limited (as the code retrieval datasets vary in the ways NL-PL pairs are collected). In this work, we propose a novel contrastive learning technique (SYNC) that enables efficient finetuning of code LMs with soft and hard negatives, where the hard negatives are constructed using a set of structure-aware AST-based perturbations; targeted towards possible syntactic and semantic variations. Our method achieves significant improvements in retrieval performance for three code LMs (CodeBERT, GraphCodeBERT, UniXCoder) over four Python code retrieval datasets.